
A importância da coleta de dados de produção já está consolidada e vem ganhando força com as obrigações de lei (Bloco K) exigidos pelo governo, necessidade de relatórios de produção, rastreabilidade, análise gráfica e publicação de indicadores chaves do processo (KPI).
Baseado nesses quesitos, como os dados da planta devem ser coletados e armazenados? Em que estrutura? Quando surge o tema de armazenamento o primeiro pensamento é dirigido para um banco de dados relacional (RDB) r os populares Sistemas de Gerenciamento de Banco de Dados (SGBD) com o SQL Server e Oracle. Porém a forma que esses bancos de dados trabalham atendem os quesitos de coleta e performance exigidos pela característica dos dados de produção?
O primeiro ponto a ser analisado é o tipo de banco de dados. Esse banco de dados citado é relacional e surgiu no início da década de 70 para atender a demanda de negócios dos escritórios corporativos. Esse modelo dominou o mercado a partir da década de 80 e responde bem as questões de negócio e facilitou a vida do gestor que precisa cruzar uma grande combinação de informações como, por exemplo, cliente, tipo de produto, localização, etc. Nesse caso poderíamos extrair informações de qual produto é mais vendido em determinada região e por qual tipo de cliente.
Mas e os dados de produção, tem a mesma característica?
Muito bem, agora vamos pensar no cenário de uma planta industrial. Os dados que alimentam o banco de dados como contagem de produção, vazão, temperatura, pressão, falhas, etc, em sua maioria, são gerados com uma frequência bastante alta na casa de segundos ou fração dessa unidade. O banco de dados Relacional não foi desenhado para um volume e velocidade de coleta tão alto. Para isso surgiram os banco de dados industriais e o termo PIMS (Plant Information Management Systems) que possuem a capacidade de coletar, armazenar e distribuir uma grande quantidade de dados com alta performance.
E quais as desvantagens ao utilizar um banco de dados relacional na coleta de dados da planta?
Baixa compressão, não atendem a velocidade e volume de dados gerados pela produção, dificuldade para tratar dados temporais, baixa performance.
E qual a vantagem do PIMS?
Desenhado para trabalhar com grande volume de dados apresenta alta taxa de compressão, alta velocidade, integração facilitada para coleta de dados de plataformas diferentes. A origem dos dados pode ser um PLC, OPC Server, CSV/XML, supervisórios (SCADA), leitores de código de barra, coleta manual, dentre outras. Do outro lado está a disponibilização com inúmeras possibilidades como exibido na ilustração abaixo:
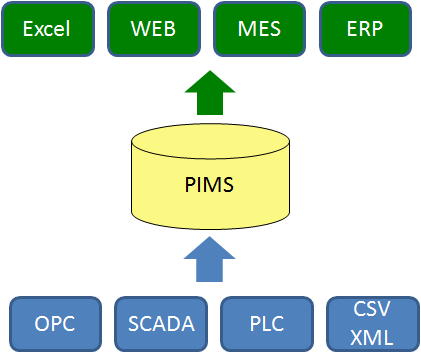
Além disso, com a alta compressão de dados, há economia no consumo de armazenamento e consequentemente no hardware necessário para alocar esse servidor.
Outro ponto de extrema importância é integração com as diversidade encontrada nas linhas de produção e processos que permite armazenar dados de várias origens em um único lugar com segurança e auditoria. A solução PIMS possui assinatura eletrônica, cálculo, logs de auditoria, histórico das variáveis armazenadas e facilidade para conexão com outros sistemas.
O primeiro passo para estruturar o fluxo e armazenamento de dados da planta é a adoção de um banco de dados industrial. Centralizar os dados e disponibilizar para as várias camadas com integridade, segurança e com velocidade exigida pelas aplicações industriais.
Lembre-se: Banco de Dados Relacional (RDB) responderá as questões do negócio, o Banco de Dados Industrial (PIMS) as demandas da produção.
Colete dados de diversas origens, armazene e disponibilize de forma correta, no momento certo, a quem precisa.